Før vi går løs på simuleringen er det noen begreper, analytisk og numerisk løsning, som vi kommer til å bruke en del. En analytisk løsning er når vi kommer fram til et svar ved å gjøre utregninger for hånd uten tanke på presisjon. En numerisk løsning er når vi lager et program som kan gå av seg selv, men finner et tilnærmet svar som vi bruker videre. Ved å bruke smarte algoritmer, sekvenser av forhåndsbestemte operasjoner, og metoder kan man får denne tilnærmingen til å komme så nærme den faktiske løsningen at forskjellen blir ubetydelig for videre utregninger. Selvfølgelig må man alltid ha presisjon i bakhuet, dette vil bli nevnt når det blir relevant.
Du har sikkert hørt om Python og Java, dette er det vi kaller for kodespråk, som betyr at de fungerer litt forskjellig. Det er alt fra språket, hvordan og hva de aksepterer og måten ting skal bli skrevet på, til hastighet på hvor lang tid de bruker på å fullføre en kode. Vi vil bruke Python til våre koder, for det er bedre egnet til den type kode vi vil lage.
Vi har gjort et par viktige antagelser som forenkler systemet og gjør modellen lettere å programmere.
- Partiklene i boksen oppfører seg som en ideell gass, altså all kollisjon er elastisk.
- Symmetrien til H2 er en enkelt kule, slik at man ikke må ta hensyn til posisjonene til hvert av atomene gjennom simuleringen.
- Det er ingen ytre og indre krefter som virker på systemet, slik som magnetiske felt, tiltrekning mellom partiklene på grunn av ladningsforskjeller og tyngdekraft osv.
- Partiklene kan ikke kollidere med hverandre, og vil dermed gå rett igjennom hverandre eller okkupere samme posisjon.
- Det skal være så tilfeldig som mulig gitt to modeller, gaussisk fordeling for fartskomponentene, og uniform fordeling for posisjonene.
- Partiklene kan bare kollidere med veggene.
- Antall partikler i boksen skal være konstant.
Hensikten bak simuleringen av partiklene er at det blir våres rakett motor, men hvordan kan dette fungere som en rakett motor, hvordan får man en netto kraft som virker i den retningen vi ønsker?
Her kommer sannsynlighetsfordelingene inn, på grunn av den gaussiske fordelingen og vår antagelse vi har en ideell gass så betyr det at energien i systemet alltid er bevart. Oppdriften vil komme av bevegelsesmengden fra partiklene som treffer veggene, men summen av denne bevegelsesmengden på hele boksen forblir lik 0 så lenge det ikke er noe hull som det kan slippes ut fra. Husk at fartskomponentene er tilfeldig fordelt fra den gaussiske modellen. Dersom det blir uklart i hvorfor dette har så mye å si så anbefaler jeg å gå tilbake til en tidligere post som dekket dette. La oss nå introdusere et hull i bunnen av boksen som partiklene kan slippes ut fra, dette gjør at ikke all bevegelsesmengden lenger motvirkes i hver sin z-retning. Tapet av bevegelsesmengden ut av hullet vil være det samme som vil virke opp i taket, som gir en bevegelse i den retningen. Denne kraften som da virker opp vil være det som får raketten til å gå oppover.
Vi har noen parametere som er bestemt på forhånd slik som antall partikler og tiden simuleringen dekker. I simuleringen vil vi bruke \(N = 10^5\) partikler, over en tid på \(t = 10^{-9}\) sekunder. Våre justerbare parametere er temperaturen gitt i kelvin, lengden på hver side av boksen med enhet \(L = 10^{-6}m\), som er 1000 ganger mindre enn en millimeter, og arealet på hullet, der hullet er et kvadrat. I tabellen under er våre startverdier satt opp, noen vil bli endret på senere.
| N | K | hull |
x |
y | z |
|---|---|---|---|---|---|
| \(10^5\) | 3000 | \(0.25L^2\) | \(1L\) | \(1L\) | \(1L\) |
Vi vet allerede tiden som simuleringen vil dekke,\(10^{-9}\) sekunder, det betyr at vi kan finne et uttrykk for kraften \(F\) ut fra impulsen. Vi kan se dette som en impuls på grunn av at vi ikke regner ut summen av bevegelsesmengden før simuleringen er ferdig, som betyr at vi kan si at bevegelsesmengden virker på boksen i et kort tidsrom, dermed kan vi skrive kraften om fra impuls slik \(Ft = \Delta p \Rightarrow F = \dfrac {\Delta p}{t}\). \(\Delta p = mv_1 - mv_0\) der \(mv_0 = 0\) som er før vi har startet simulasjonen, og \(mv_1 = m\sum v_{total}\) som er total bevegelsesmengde fra alle partiklene som forlot boksen under hele simulasjonen.
Kan du tenke deg hvorfor vi kan sette \(m\) utenfor summeringstegnet \(\sum\)?
Fartskomponentene blir bestemt ut fra en gaussisk fordeling, men posisjonene er bestemt av uniform fordeling. Uniform fordeling betyr at det er like stor sannsynlighet at en partikkel blir plassert i midten av boksen som et hvilket som helst annet sted i boksen. Et eksempel som kan visualisere dette bedre er om vi deler hver side opp i 20 like store deler for så å skulle kaste en 20 siders terning, og tallet man får bestemmer posisjonen i den gitte retningen. Denne prosessen gjøres så en gang for hver retning og hvert kast er uavhengig av hverandre, dermed får man en uniform fordeling på posisjonene i boksen. Dette gjøres 3 ganger for hver partikkel og med både fartskomponentene og posisjonene på plass er vi nesten klare til å starte simuleringen.
Posisjon og fart er på plass, så kommer vi til hvordan vi får disse til å bevege seg. På grunn av noen begrensninger kan man ikke gjøre mer enn en ting om gangen i Python, det betyr at når vi skal bevege partiklene så må dette gjøres komponent etter komponent, partikkel etter partikkel. Som du kanskje innser så blir dette en lang prosess for \(N = 10^5\) partikler. Måten vi får de til å bevege seg er gjennom å bruke noen av de grunnleggende formlene for fart, strekning og tid. Farten i en gitt retning har vi, og tiden vil være det vi kaller for et tidssteg.
Så hva er poenget med et tidssteg? Under de fleste numeriske måter å simulere ting på, slik som nå, buker man steglengden for å justere på presisjonen. Mindre steglengde betyr større presisjon på bekostning av tiden det tar å kjøre koden på grunn av at den må gjøre samme prosess flere ganger for å dekke samme tidsramme. Likeså er det for større steglengde, større steg betyr mindre presisjon, men raskere utføring av koden. I vårt tilfelle vil vi bruke tidssteg på \(\Delta t =dt = 10^{-12} \), med litt enkel regning får vi at antall steg er lik 1000. Det betyr at vi skal flytte på hver partikkel 1000 ganger. Vi kan skrive dette som \(posisjon_1 = posisjon_0 + v \cdot dt\). Vi vil også bruke noe som kalles en "loop" for å få dette til å gå av seg selv, som vil gå igjennom hver partikkel og oppdatere, eller gi, dem en ny posisjon. Når dette har skjedd og den er ferdig med den siste partikkelen går den tilbake til den første partikkelen og gjør det samme igjen. Dette kalles en iterasjon, en repetitive handling, som gjøres 1000 ganger. Dette kalles for Euler's metode, og vi kunne ha brukt mange andre variasjoner som kunne ha ulik presisjon, men for vårt tilfelle så holder det lenge med den standard versjonen. Hadde vi hatt med akselerasjon ville ikke denne fungere, og vi ville ha brukt en variasjon som heter Euler Cromer. Denne kommer vi til litt senere så vi kan vente med å forklare den til da.
Det er på tide å påpeke hva vi gjør for å oppdage om en partikkel har kollidert i en vegg. Veggkollisjon blir oppdaget dersom den nye posisjonen er utenfor en av sidene. Ta for eksempel i x-retning, origo er plassert midt på x, som betyr at lengden x i positiv og negativ retning er \(\pm \dfrac{1}{2}x \) der \(x = 1L\). På bilde under er det et eksempel på en kollisjon med veggen. Her vil den nye posisjonen bli justert slik at det går tilbake i motsatt retning, så partikkelen holder seg inne i boksen, samtidig som fartskomponenten i den retningen vil endre retning. Det er andre måter å gjøre dette på, som for eksempel å bare se om det er utenfor og flytte den slik at de er akkurat inne i boksen, inkludert å endre fortegnet på farten i den retningen. Denne måten å implementere veggkollisjon er definitivt lettere, men man mister hele lengden som partikkelen tilbakela utenfor boksen. I vår simulering blir dette også tatt hensyn til, og partikkelen kan være så langt unna som den vil, og fremdeles bli plassert inne i boksen, med fortegnet til fartskomponenten endret med hensyn på hvilken retning den ville ha fortsatt i. Det betyr at vi har mulighet å få partikler med flere veggkollisjoner under samme tidssteg. Dette går dessverre på bekostning av tiden det tar å kjøre koden på grunn av de ekstra beregningene som må gjøres for å få dette til å fungere.
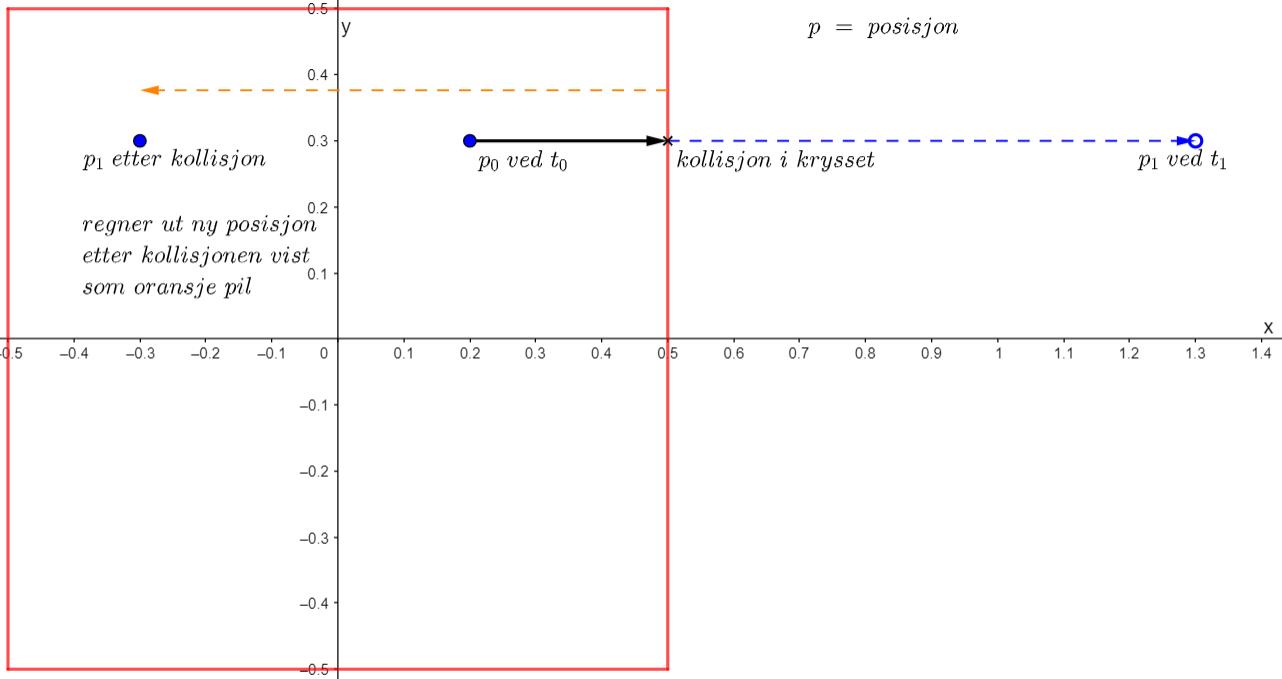
Hva om en partikkel går gjennom hullet, hva gjør vi med dem? For veggkollisjon brukte vi noe vi kaller for reflective boundary condition, for partikler som går ut av hullet bruker vi noe vi kaller for periodic boundary condition. Man kan tenke på det som om man teleporterer partikkelen tilbake inn i boksen fra toppen av med en avstand fra taket lik den avstanden den tilbakela utenfor boksen. Med andre ord, vi trekker fra den nye posisjonen med en lengde lik høyden av hele boksen. I praksis blir det egentlig å legge til fordi posisjonen vil alltid ha et negativt fortegn på grunn av plasseringen av hullet. Dette er en metode som er moderat når det kommer til hvordan det vil påvirke farten på koden. Enklere metoder som å bare la hullet være som en vegg og bare registrere når en partikkel treffer innenfor hadde vært lettere, men det vil ikke akkurat kunne simulere helt det samme som skjer under påfyll av drivstoff til motoren.
Det er også bedre enn å bare plassere dem i en fast z verdi for da mister man noe av tilfeldighetene man satt helt i starten, for da får man et slags system som vil motvirke entropien i systemet. Den måten vi valgte vil både kunne simulere det som skjer i motoren, når nye partikler blir sendt inn for å erstatte det som ble mistet, og bevare tilfeldigheten i systemet på en bedre måte. Alt vi trenger å gjøre er å telle antall som går ut gjennom hullet, samle deres vz og endre på pz.
Med det er vi nesten klare, bare en ting til og det er oppsamling av dataene. Når simulasjonen er ferdig vil den returnere en liste med følgende verdier og på den følgende formen.
|
|
|---|
Så hva er denne tabellen med mindre tabeller i seg? Dette er en kombinasjon av to måter å lagre verdier på, den første som inneholder begge tabellene kalles en liste. Den andre typen som hver av de mindre tabellene er kalles en array. "Hva er da forskjellen" lurer du nok sikkert på nå. En liste kan inneholde mange ulike typer objekter, deriblant andre lister med ting, en array kan bare ha tall verdier, men er i motsetning til lister enklere å bruke dersom man skal regne ut nye verdier, inkludert mye raskere. Når vi leser av resultatet er vi hovedsakelig bare interessert i de to siste verdiene, resten er dersom vi trenger å sammenligne dersom vi skulle trenge å endre på verdiene.
- N = antall partikler brukt i simulasjonen
- k = temperatur i boksen
- A = arealet av hullet
- s = seed, en verdi brukt under fordeling av fartskomponentene og posisjonene som gjør at vi får samme fordeling hver gang vi kjører koden så lenge denne verdien er det samme. I vår simulering brukte vi verdien seed = 75.
- xl = lengden på boksen langs x-aksen gitt i L = 10-6 m
- yl = lengden på boksen langs y-aksen gitt i L = 10-6 m
- zl = lengden på boksen langs z-aksen gitt i L = 10-6 m
- ntot = antall partikler som gikk ut gjennom hullet gjennom hele simulasjonen.
- Vtot = samlet mengde av absolutt verdien av vz fra partiklene som forlot boksen gjennom hele simulasjonen. Trenger bare å samle vz fordi det bare er en type partikkel som gjør at å legge sammen massen ganget med individuelle fartskomponenter blir det samme som å legge sammen komponentene først, for så å gange det med massen.
Brukte disse parameterne da vi kjørte koden første gang
| N = 105 | k = 3000 | A = 0.25L2 | x = 1L | y = 1L | z = 1L |
|---|
og fikk følgende resultat
| ntot = 4.3076 * 104 | Vtot = 2.00004018 * 108 m/s |
|---|
Nå gjelder det å se hvor godt dette stemmer med det vi forventer. For å sjekke dette bruker formelen for den midlere farten som partiklene vil ha som er \(\langle v \rangle = \int_{0}^{\infty} v P\left(v\right) \, dv\), har ikke tenkt til å ta utledningen her, men du kan gå hit dersom du er interessert i utledningen. Dette integralet blir så \(\langle v \rangle = \sqrt{\dfrac{8 kT}{\pi m}}\).
Her legger vi inn verdiene for den analytiske løsningen og bruker at \(k = 1.38 \cdot 10^{-23} J/K\) som er Boltzmannkonstanten, og massen for H2 blir \(m_{H_2} = 2.018 \cdot 1.66 \cdot 10^{-27}\) kg, setter inn verdiene og får \(\langle v \rangle = 5612.68 m/s \). Tar så å deler \(\langle v_{numerisk} \rangle = V_{tot}/n_{tot} \) som blir 4643 m/s, dette gir oss en for stor prosent del når vi ser på presisjonen mellom det den ga, og det som er å forvente.
Måten vi regner ut det er \(\dfrac{absolutverdi(numerisk - analytisk)}{analytisk}\) i vårt tilfelle er dette på 17.3%, som betyr at verdiene er rundt 17.3% for høye.
Det betyr at noe ikke fungerte som det skulle, som er mest sannsynlig noe å gjøre med hvordan vi gikk lagret verdiene, eller andre småfeil i koden. Mye tyder på at det er tekniske feil som avrundingsfeil gjort under veggkollisjonene og andre småting som er vanskelig å fikse.
Noe som er verdt å merke seg er at 2 versjoner av koden ble laget, eneste forskjell mellom dem var måten vi lagret verdiene på, men de ga ulikt resultat. Vi fortsatte med denne versjonen som hadde endret på måten vi lagret verdiene på, for det var et fokus på at det skulle være en pc-vennlig kode å kjøre, den andre kunne fort føre til at pc'en gikk tom for minne selv om den første var mer presis ut fra å gjøre en test. Det kan fremdeles ha vært like dårlig presisjon, men presisjonen er ikke det som var hovedfokuset.
Dette er en typisk ting som er vanskelig å forutse når det kommer numeriske løsninger, det er alltid et forhold mellom presisjon, utførings tid og bruk av ressurser for en pc, og denne gangen var det presisjonen som fikk støyten.
Da har vi det vi trenger for å skyte opp raketten vår. Fortsetter i neste blogg-post, eller gå til forrige blogg-post.
Under er det en video for moro skyld som viser boksen med alle de 100 000 partiklene, den ble laget med hjelp av en modifisert versjon av koden, visualisert ved hjelp av et program som heter ovito, og er en tidligere versjon, så den har ikke implementert hullet i simulasjonen. UIO sin nettside(denne) var ikke helt fornøyd med å skulle vise videoen så det kan være litt hakkete.