Oppgave 1 - Differansetransform og Huffman-koding
a)
Histogrammet til gråtonebildets intensitetsverdier er h = [11 22 15 6], dvs. at h(0) = 11, h(1) = 22, h(2) = 15 og h(3) = 6. Fra dette histogrammet ser vi at Huffman-algoritmen vil:
I. Slå sammen gruppen som består av 3 og gruppen som består av 0, som gir en ny gruppe med total forekomst på 17.
II. Slå sammen gruppen som består av 2 og gruppen som består av 0 og 3, som gir en ny gruppe med total forekomst på 32.
III. Slå sammen gruppen som består av 1 og gruppen som består av 0, 2 og 3.
Totalt gjør dette at lengdene av Huffman-kodeordene blir 3, 1, 2 og 3 for henholdsvis intensitet 0, 1, 2 og 3, noe som gir et gjennomsnittlig antall biter per piksel etter Huffman-koding av dette bildet på omtrent 1,91.
b)
Differansetransformen av bildet er:
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 | -1 | 0 | 2 | 0 | 0 |
| 1 | -1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | -1 | 1 | 0 | 1 | -1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | -1 | 0 | 0 | 2 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | -1 | 1 |
c)
Histogrammet til differansebildet er gitt ved h(-1) = 6, h(0) = 29, h(1) = 17 og h(2) = 2, som kan skrives som h = [6 29 17 2] under forståelse om at intervallet er heltallene mellom -1 og 2. Det er greit å innse at Huffman-algoritmen vil resultere i nøyaktig samme kodebok for dette histogrammet som for histogrammet til det opprinnelige gråtonebildets intensitetsverdier (se deloppgave a)), med unntak av at intensitetsverdiene som Huffman-kodeordene representerer nå er byttet ut med differanseverdier som har én lavere verdi. Dermed vil lengdene av Huffman-kodeordene være 3, 1, 2 og 3 for henholdsvis differansene -1, 0, 1 og 2, noe som gjør at vi vil bruke omtrent 1,61 biter per piksel i gjennomsnitt etter Huffman-koding av differansebildet.
d)
Entropien av gråtonebildet gir en nedre grense for hvor kompakt gråtonebildet kan kodes dersom vi bare koder ett piksel om gangen. Videre vet vi at denne grensen bare oppnås når alle sannsynlighetene i det normaliserte histogrammet kan skrives som 1/2k for (muligens forskjellige) heltallige k. Ettersom dette kravet ikke er oppfylt i det opprinnelige gråtonebildet, er det en nødvendighet at Huffman-kodingen resulterer i et gjennomsnittlig antall biter per piksel som er høyere enn entropien.
Når vi bruker differansetransformen ser vi ikke bare på ett piksel om gangen. Å Huffman-kode differansebildet endrer ikke dette; i den totale kompresjonsprosedyren vil man (forsøke å) både redusere intersampel redundans (ved differansetransformen) og kodingsredundans (Huffman-kodingen). Entropien til det opprinnelige gråtonebildet gir ikke noen nedre grense for kompresjonsraten i dette tilfellet, og det er derfor mulig å oppnå høyere kompresjonsrater enn entropien tilsier (som vi gjør her).
Bemerkning: Siden vi Huffman-koder differansebildet vil entropien av differansebildet gi oss en nedre grense for hvor mange biter per piksel vi i gjennomsnitt må bruke etter kodingen (denne entropien er et mål på informasjonen i differansebildet når vi ser på differanseverdiene enkeltvis). Denne entropien er omtrent 1,53, så vi ser at også her vil Huffman-kodingen resultere i lav kodingsredundans.
Oppgave 2 - Løpelengdetransform og Huffman-koding
... og "differansetransform" i tid
a)
Histogrammet til gråtonebildets intensitetsverdier er h = [6 19 21 8], dvs. at h(0) = 6, h(1) = 19, h(2) = 21 og h(3) = 8. Fra dette histogrammet ser vi at Huffman-algoritmen vil:
I. Slå sammen gruppen som består av 0 og gruppen som består av 3, som gir en ny gruppe med total forekomst på 14.
II. Slå sammen gruppen som består av 0 og 3 og gruppen som består av 1, som gir en ny gruppe med total forekomst på 33.
III. Slå sammen gruppen som består av 2 og gruppen som består av 0, 1 og 3.
Totalt gjør dette at lengdene av Huffman-kodeordene blir 3, 2, 1 og 3 for henholdsvis intensitet 0, 1, 2 og 3, noe som gir et gjennomsnittlige antall biter per piksel etter Huffman-koding av dette bildet på omtrent 1,87.
b)
Resultatet etter og utført løpelengdetransformen på hver rad blir:
- (0,2), (1,3), (2,4)
- (0,2), (1,4), (2,3)
- (1,2), (0,2), (1,2), (2,3)
- (1,2), (2,4), (3,3)
- (1,3), (2,4), (3,2)
- (1,3), (2,3), (3,3)
c)
Histogrammet til tallparenes intensitetsverdier er h = [3 7 6 3], dvs. at h(0) = 3, h(1) = 7, h(2) = 6 og h(3) = 3. Fra dette histogrammet ser vi at Huffman-algoritmen vil:
I. Slå sammen gruppen som består av 0 og gruppen som består av 3, som gir en ny gruppe med total forekomst på 6.
II. Slå sammen gruppen som består av 0 og 3 og gruppen som består av 2, som gir en ny gruppe med total forekomst på 12.
III. Slå sammen gruppen som består av 1 og gruppen som består av 0, 2 og 3.
Totalt gjør dette at lengdene av Huffman-kodeordene blir 3, 1, 2 og 3 for henholdsvis intensitet 0, 1, 2 og 3, noe som gjør at Huffman-koden vil bruke 37 biter på å representere disse intensitetene.
Histogrammet til tallparenes løpelengder er gitt ved h(2) = 7, h(3) = 8 og h(4) = 4, som kan skrives som h = [7 8 4] under forståelse om at intervallet er heltallene mellom 2 og 4. Det er rimelig enkelt å innse at Huffman-algoritmen vil først kombineres 4 og 2, for så å kombinere 3 med den forrige kombinasjonen. Dermed vil lengdene av Huffman-kodeordene blir 2, 1 og 2 for henholdsvis løpelengde 2, 3 og 4, noe som gjør at Huffman-koden vil bruke 30 biter på å representere disse løpelengdene.
Siden det er 54 piksler i det opprinnelige bildet, vil det gjennomsnittlige antall biter per piksel etter denne kompresjonsprosedyren bli omtrent 1,24.
d)
Histogrammet til tallparene er [3 3 3 1 3 3 1 2] under forståelsen av at posisjonene i histogrammet representerer henholdsvis tallparet (0,2), (1,2), (1,3), (1,4), (2,3), (2,4), (3,2) og (3,3). Fra dette histogrammet ser vi at Huffman-algoritmen vil:
I. Slå sammen gruppen som består av (1,4) og gruppen som består av (3,2), som gir en ny gruppe med total forekomst på 2.
II. Slå sammen gruppen som består av (3,3) og gruppen som består av (1,4) og (3,2), som gir en ny gruppe med total forekomst på 4.
III. Slå sammen gruppen som består av (2,3) og gruppen som består av (2,4), som gir en ny gruppe med total forekomst på 6.
IV. Slå sammen gruppen som består av (1,2) og gruppen som består av (1,3), som gir en ny gruppe med total forekomst på 6.
V. Slå sammen gruppen som består av (0,2) og gruppen som består av (1,4), (3,2) og (3,3), som gir en ny gruppe med total forekomst på 7.
VI. Slå sammen gruppen som består av (1,2) og (1,3) og gruppen som består av (2,3) og (2,4), som gir en ny gruppe med total forekomst på 12.
VII. Slå sammen gruppen som består av (0,2), (1,4), (3,2) og (3,3) og gruppen som består av (1,2), (1,3), (2,3) og (2,4).
Totalt gjør dette at lengdene av Huffman-kodeordene blir 2, 3, 3, 4, 3, 3, 4 og 3 for tallparene når de er oppgitt i samme rekkefølge som i histogrammet, noe som gjør at Huffman-koden vil bruke 56 biter på å representere disse tallparene. Siden det er 54 piksler i det opprinnelige bildet, vil det gjennomsnittlige antall biter per piksel etter denne kompresjonsprosedyren bli omtrent 1,04.
e)
Differansebildet blir:
| 0 | 0 | -1 | 0 | 0 | -1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | -1 | -1 | 0 | 0 | 0 |
| 0 | -1 | 0 | 0 | 0 | 0 | -1 | 0 | 0 |
| 0 | -1 | -1 | -1 | 0 | -1 | -1 | 0 | 0 |
| 0 | 0 | 0 | 0 | -1 | -1 | -1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1 | 0 |
Dette bildet inneholder kun to forskjellige symboler, noe som gjør at vi både kan og må bruke 1 bit per piksel for å kode dette bildet dersom vi skal kode hvert symbol for seg selv.
Oppgave 3 - Løpelengdetransform av binære bilder
a)
Hvis vi har N løpelengder i en rad så kommer vi til å bruke nN biter for å representere dette med en n-biters naturlig binærkode, mens vi trenger 2n-1 biter for å representere raden uten kompresjon. For å oppnå plassreduksjon så må løpelengderepresentasjonen ta mindre biter enn det ukomprimerte bildet, altså må nN < 2n-1, noe som vi kan omskrive til N < (2n-1)/n.
b)
For n=4 får vi: N < (24-1)/4 = 15/4 (= 3,75). Altså må antall løpelengder i raden være mindre eller lik 3 for å oppnå plassreduksjon når n=4. PS: Antall piksler i raden er da 24-1 = 15, så middelverdien av løpelengdene må minst være 15/3 = 5 for at vi skal oppnå kompresjon.
For n=8 får vi: N < (28-1)/8 = 255/8 (= 31,875). Altså må antall løpelengder i raden være mindre eller lik 31 for å oppnå plassreduksjon når n=8. PS: Antall piksler i raden er da 28-1 = 255, så middelverdien av løpelengdene må minst være 255/31, omtrent 8,23, for at vi skal oppnå kompresjon.
For n=10 får vi: N < (210-1)/10 = 1023/10 (= 102,3). Altså må antall løpelengder i raden være mindre eller lik 102 for å oppnå plassreduksjon når n=10. PS: Antall piksler i raden er da 210-1 = 1023, så middelverdien av løpelengdene må minst være 1023/102, omtrent 10,03, for at vi skal oppnå kompresjon.
c)
Forholdet mellom "bredden på bildet" og den øvre grensen til "det høyeste antall løpelengder vi kan ha og fortsatt oppnå kompresjon" er (2n-1) / ((2n-1)/n) = n.
Dette forholdet angir en nedre grense for hva middelverdien av løpelengdene kan være og vi fortsatt oppnår kompresjon; middelverdien av løpelengdene må være ekte større enn n for at vi skal oppnå kompresjon.
Kombinert med uttrykket fra deloppgave a) har vi derfor at: For store bilder kan vi tillate oss å ha mange løpelengder (den øvre grensen for N er da stor), men likevel må hver løpelengde være større i gjennomsnitt enn for mindre bilder (n stiger, dog ganske langsomt sett i sammenheng med at den definerer bildets bredde ved 2n-1).
Oppgave 4 - Løpelengdetransform, differansetransform og Huffman-koding
a)
Hver rad vil bestå av 8 løpelengder, og alle løpelengdene er lik 512/8 = 64. Ved bruk av 8-biters naturlig binærkoding av både intensitetsverdier og løpelengder så vil vi totalt bruke 8 * (8*2 + 2) = 8*18 = 144 biter per rad.
b)
Bildet inneholder 512 like rader. Derfor vil Huffman-koden av en rad være den samme som Huffman-koden av hele bildet.
Etter løpelengdetransform kan hver rad skrives som: 0 64 32 64 64 64 96 64 128 64 160 64 192 64 224 64 0 0. Vi kan bruke disse hyppighetene til å finne et Huffman-kodetre:
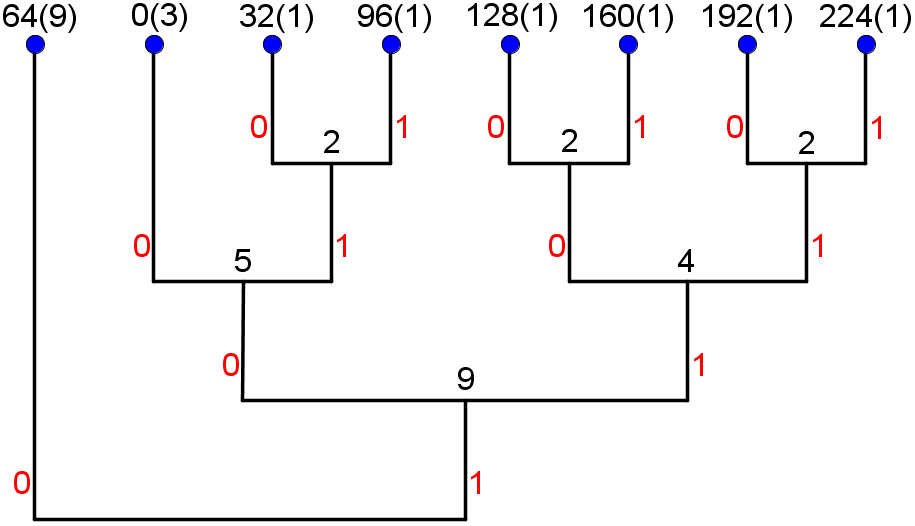
Dette gir oss følgende Huffman-kodebok:
| Symbol | 0 | 32 | 64 | 96 | 128 | 160 | 192 | 224 |
|---|---|---|---|---|---|---|---|---|
| Huffman-kodeord | 100 | 1010 | 0 | 1011 | 1100 | 1101 | 1110 | 1111 |
| Antall forekomster | 3 | 1 | 9 | 1 | 1 | 1 | 1 | 1 |
c)
Fra tabellen over ser vi kodeordet og antall forekomster av hvert symbol for hver rad. Multipliserer vi hver kodeordlengde med de tilhørende hyppighetene så får vi det totale antall biter som blir brukt til å representere løpelengdetransformen og EOL-merket; 1*9 + 3*3 + 6*(4*1) = 9+9+24 = 42 biter per rad. Siden det er 512 piksler per rad i det opprinnelige bildet, tilsvarer dette et gjennomsnittlig bitforbruk per piksel på 42/512 = 21/256, som er omtrent 0,08. Ettersom vi bruker 8 biter per piksel i det ukomprimerte bildet, får vi en omtrentlig kompresjonsrate på 8/0,08 = 100 (eksakt regning hadde gitt omtrent 97,5). Siden alle radene er like vil både bitforbruket og kompresjonsraten gjelde for hver rad såvel som for hele bildet.
Hvis det hadde blitt bedt om å beregne det gjennomsnittlige antall biter per løpelengdekoeffisient (altså, per ene verdi av løpelengdeparene), inklusivt EOL-merket, ville svaret vært 42/18 = 7/3, som er omtrent 2,33.
d)
I det opprinnelige bildet er det åtte forskjellige gråtoner og alle er like sannsynlige. Dette gjør at enhver 3-biters binærkode som tilordner kodeord til de åtte forskjellige gråtonene er en optimal kode når vi koder enkeltpiksler. Kompresjonsraten blir da 8/3.
(Vi kunne i stedet argumentert med at entropien til dette bildet er eksakt 3; 8*(-(1/8)log2(1/8)) = 8*3/8 = 3, og videre at dette optimumet opplagt kan oppnås i dette tilfellet, nettopp ved en 3-biters binærkode.)
I det differansetransformerte bildet så vil vi for hver rad finne sju elementer lik 32 (ved overgangen mellom "trappetrinnene"), mens ellers bare 0 (i alle de andre 505 elementene). Ettersom det bare finnes to verdier i bildet, vil ett bit per piksel være det beste vi i praksis kan oppnå når vi bare koder enkeltdifferanser. Vi får dermed en kompresjonsrate på 8/1= 8. Altså får vi 3 ganger høyere kompresjonsrate etter differansetransformen enn originalt, dersom vi i begge tilfeller koder enkeltsymboler på en best mulig måte.
Oppgave 5 - Lempel-Ziv-Welch-transform
a)
Fra det oppgitte histogrammet ser vi at én gyldig fremgangsmåte for Huffman-algoritmen er:
I. Slå sammen gruppen som består av "b" og gruppen som består av "c", som gir en ny gruppe med total forekomst på 15.
II. Slå sammen gruppen som består av "a" og gruppen som består av "d", som gir en ny gruppe med total forekomst på 21.
III. Slå sammen gruppen som består av "a" og "d" og gruppen som består av "b" og "c".
I den resulterende Huffman-kodingen vil alle kodeordene ha lengde 2. Siden Huffman-koding er optimal under begrensningen at vi koder enkeltsymboler, så betyr dette at alle kodinger der alle kodeordene har lengde 2 er optimale på samme måte som Huffman-koden. Naturlig binærkoding er én slik koding.
b)
Følg oppskriften for senderen og du vil ende opp med følgende LZW-kodesekvens: 0 1 4 2 6 3 8 0 10 9 12 7 14.
c)
Kodesekvensen fra deloppgave b) inneholder 13 koder, og med naturlig binærkoding bruker vi 4 biter på å representere hver av dem. Totalt vil vi derfor bruke 4*13 = 52 biter på den første meldingen. Siden denne meldingen inneholder 36 symboler, tilsvarer dette et gjennomsnittlig bitforbruk per symbol (av den opprinnelige meldingen) på 52/36 = 13/9, som er omtrent 1,44.
d)
Entropien setter en nedre grense for hvor mange biter vi i gjennomsnitt trenger per symbol når vi koder symbolene enkeltvis, men LZW-transformen koder ikke symbolene enkeltvis. Dermed er ikke naturlig binærkoding av LZW-kodene begrenset av entropien slik som Shannon-Fano-koding og Huffman-koding er.
(Vi kunne alternativt argumentert med at LZW-transformen prøver å redusere både intersampel redundans og kodingsredundans, og at entropien kun er knyttet til kodingsredundansen.)
e)
Følg oppskriften for senderen og du vil ende opp med følgende LZW-kodesekvens: 0 1 1 2 3 1 4 0 2 11 3 0 0 14 15 2 7 4 7 14 8 18 7 1.
f)
Kodesekvensen fra deloppgave e) inneholder 24 koder, og med naturlig binærkoding bruker vi 5 biter på å representere hver av dem. Totalt vil vi derfor bruke 5*24 = 120 biter på den andre meldingen. Siden denne meldingen inneholder 36 symboler, tilsvarer dette et gjennomsnittlig bitforbruk per symbol (av den opprinnelige meldingen) på 120/36 = 10/3, som er omtrent 3,33.
g)
LZW-transformen utnytter mønstre i meldingen. Et nødvendig kriterium for at LZW-transformering skal resultere i plassreduksjon er derfor at det finnes mønstre i meldingen som komprimeres. Det vil det normalt ikke gjøre i en melding som består av symboler som er plassert på tilfeldige posisjoner i meldingen, som i den andre meldingen i denne oppgaven.