Hva er en Webservice(WS)?
En Webservice (WS) er en del av en tjeneste eller system som tilbyr lese- og/eller skrivetilgang til tjenesten eller systemet vha. webbasert teknologi. En WS kan være en integrert del av tjenesten (heretter vil "tjeneste" dekke både system og tjeneste), en modul til tjenesten eller en løsrevet komponent som har et eget livsløp. Felles for alle variasjoner er at de gir et standardisert grensesnitt til å lese og/eller skrive data som ligger i tjenesten.
En WS tilbyr ett eller flere API-er som tilbyr funksjoner opp mot tjenesten. Funksjonene kan være nærmest hva som helst, men som regel er de av typen "hent data fra kilden".

Hva er hensikten?
Dagens situasjon
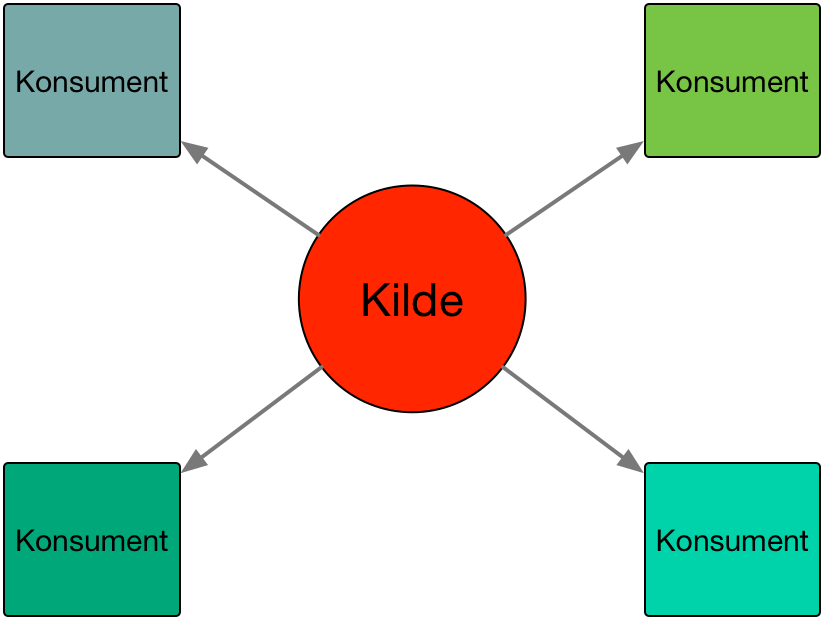
Hensikten med å gå over på en WS-basert integrasjonsarkitektur er primært å kvitte seg med flaskehalser i organisasjonen, samt forhindre dobbeltarbeid. Mange av UiOs integrasjoner er basert på en såkalt "hub&spoke"-modell der datakilden er ansvarlig for å levere fra seg de data som en konsument trenger. Årsakene til at dette har blitt en så vanlig modell for integrasjon er mange, der de viktigste er:
- sikkerhet - kun de ansvarlige for kilden skal få tilgang til dataene i kilden
- kompleksitet - kun de ansvarlige for kilden forstår datamodellen i kilden
- sentralisering - som en følge av sentralisering av data så blir integrasjonene også sentraliserte
- tradisjon - slik at man "alltid" gjort integrasjon
Det er store utfordringer knyttet til en slik "hub&spoke"-modell. Sentralisering av data er et veldig fornuftig valg for å bekjempe dårlig datakvalitet og sikre en autoritativ kilde som konsumenter kan forholde seg til. Sentralisering av integrasjonene nyter ikke de samme godene:
- De tekniske ressursene tilknyttet kilden blir bundet opp i enkeltprosjekter, andre prosjekter må vente.
- En endring ute i en konsument medfører at ressurser må endre på kilden.
- Kilden må alltid ha mange tekniske ressurser tilknyttet for å klare arbeidsmengden.
- Prosjekter får store skjulte kostnader fordi ressurser i kilden må gjøre integrasjonen.
- Prosjekter blir forsinket da det sjelden er nok tekniske ressurser tilknyttet kilden og ingen andre enn disse ressursene kan gjøre integrasjonen.
En WS-basert modell
To av problemene som har medført at "hub&spoke"-modellen har blitt så utbredt er sikkerhet og kompleksitet. Uten grensesnitt som adresserer disse problemene så vil det være vanskelig å gjøre en omfattende endring i hvordan UiO gjør integrasjon. Sikkerhetsproblemet består i hovedsak at systemeiere ikke vil tillate andre tilganger rett i databaser eller til API-er inne i tjenesten. Det er lite eller ingen tilgangskontroll så skal noen ha tilgang til noe så får de det til alt - gjerne også muligheten til å endre data.
Kompleksitetsproblemene er ofte at internt i en tjeneste så er data strukturert på en slik måte at de gir mening for systemeiere og ressurser tilknyttet tjenesten, men ikke utenforstående. Så selv om man gir tilgang til en kilde så betyr ikke det at konsumenten skjønner hva kilden tilbyr eller får gale data.
Dette kan løses som en del av WS-modellen:
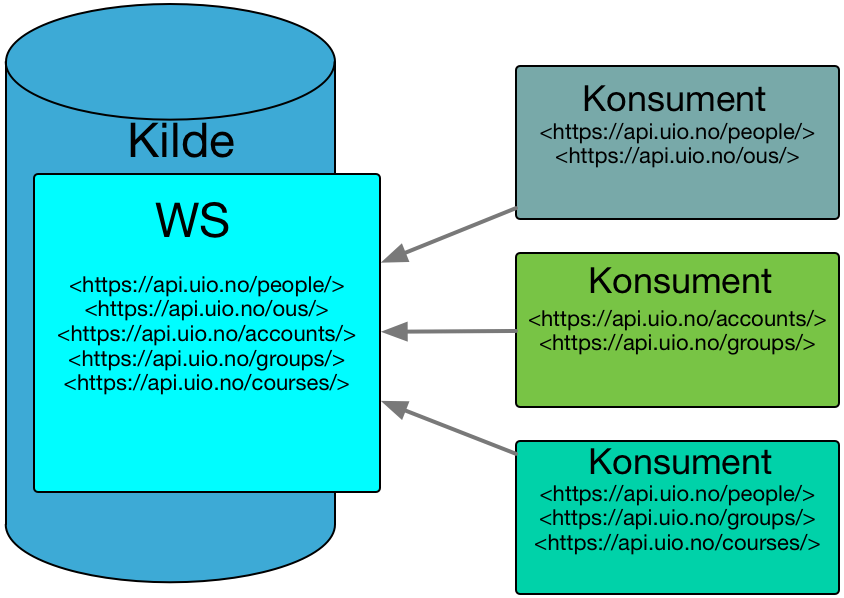
Hvordan API-et utformes i WS-en vil adressere kompleksitetsproblemene som nevnt. Hvis konsumenter trenger å finne alle kontoer på UiO så kan API-et tilby en vasket liste der alle aktive konti som oppfyller kravene vises. Interne data, som ikke er interessante for andre enn systemeier, vises ikke.
Systemeier for kilden og de tekniske ressursene tilknyttet kilden vil være ansvarlige for å tilby et API som gir konsumenter de data som konsumentene trenger. I oppstart av WS-basert integrasjon vil kostnaden knyttet til integrasjon være likt med tidligere måter å integrere på. Det er når WS-en allerede tilbyr et rikt API at systemeier vil se gevinsten i mindre behov for å bruke ressurser på integrasjon – prosjektene vil selv kunne skaffe data gjennom WS-en. Prosjektene kan budsjettere med tid og ressurser for integrasjon uten at kilden er en flaskehals.
API manager
En API manager, også kalt API gateway, er en tjeneste for å kontrollere og styre tilganger til API-er. Tjenesten sikrer at konsumenter er de de utgir seg for å være (autentisering) og holder rede på de tilganger konsumentene skal ha (autorisasjon).

Ved å sentralisere tilgangsstyringen av API-er så høster vi en rekke fordeler:
- Ett sentralt punkt for tilgangsstyring
- bestilling av flere tilganger i flere API-er kun ett sted
- forvaltning av tilganger i flere kilder kun ett sted
- Sentral oversikt over dataflyt
- bedre sikkerhet
- oversikt over hele virksomheten
- Ett punkt for integrasjon
- konsumenter må ikke lete etter ulike API-er
- konsumenter kan integrere en gang, ulike kilder gir tilgang

Meldingskø (MQ)
En meldingskø (MQ) er en tjeneste som gir kilder mulighet til å sende beskjed om at data er endret. I gamle hub & spoke-integrasjoner baserer man seg i stor grad på fulldumper – altså filer med alle data en konsument trenger. Dette er kostbart, sårbart og tregt. Med en meldingskø er tanken at en kilde sender ut en notifikasjon når data har endret seg, som er av interesse for konsumenter. Notifikasjonen er ikke nødvendigvis informasjonsbærende nok til at konsumenten kan foreta en endring, men forteller konsumenten at den må hente data på nytt for å sjekke egne data mot den autoritative kilden. Dette gjøres med en URL til den berørte enheten.

Notifikasjoner skal ikke inneholde utfyllende informasjon fordi man ønsker liberale regler rundt abonnement på notifikasjoner. Flyter fødselsnummer eller sensitiv informasjon i notifikasjoner så må tilgangskontrollen på notifikasjoner være strengt regulert. Er notifikasjonene kun en indikator på at noe har skjedd med en enhet så vil tilgangskontrollen kunne gjøres ene og alene mot WS-en.
MQ, som beskrevet i arkitekturen og i dette dokumentet, er en sentral tjeneste. Andre meldingskøer kan eksistere i virksomheten uten at de faller inn under arkitekturen. Sammenhengen mellom API manager, WS og MQ forklares lenger ned i dokumentet.
Hvem må ha en WS?
Det er ikke slik at alle tjenester må ha en WS i den nye integrasjonsarkitekturen. Kravet om WS inntreffer hovedsaklig når en kilde sitter på data som andre tjenester vil lese og eller skrive. Har kilden svært få integrasjoner og dette ikke vil øke i fremtiden så vil integrasjonsarkitekturprinsippene heller ikke kreve en WS foran kilden. Det gir for lite avkastning på investeringen.
WS vil være enten påkrev eller svært nyttig der tjenesten er en autoritativ kilde for data som andre trenger innsyn i, eller der tjenesten fungerer som en del av en annen tjeneste.
Autoritativ kilde
Mange av integrasjonene på UiO kommer av at tjenester trenger noe data fra en autoritativ kilde. Eksempler er lister av alle personer, konti eller grupper. Hva disse dataene brukes til videre er forskjellig, men likhetstrekkene for selve integrasjonen er så markant at man får store fordeler av å modernisere og standardisere prosessen.

En tenkt flyt i modellen over er:
- Kilde sender notifikasjon med innhold "person 123 er endret" til MQ som følge av at et telefonnummer er endret.
- MQ videresender notifikasjonen til de konsumenter som abonnerer på denne typen notifikasjoner fra kilden.
- Konsumenten får beskjed om at person 123 har en ukjent endring.
- Konsumenten kontakter API manager, som styrer tilgangen til WS-en til kilden, for å spørre om personobjektet 123.
- Alle kall til API manager, og som er forhåndsgodkjent, videresendes til WS-en.
- WS-en returnerer personobjektet 123, med det oppdaterte telefonnummeret.
- Konsumenten sammenligner nye og gamle data og oppdaterer telefonnummeret.
Datalager
Integrasjoner er ikke alltid det å flytte data fra A til B, altså replisering av data. Sammensatte tjenester der man utnytter en tjenesteorientert arkitektur vil kunne bygge på andre tjenester. Et eksempel på dette kan være at en tjeneste velger å integrere med en kilde med den hensikt å benytte kilden som en del av sitt datalager. Tjenesten kunne integrert som over og replisert data om f.eks. personer, grupper eller kalenderdata, men man kan også gå direkte til kilden (bokstavelig talt) og jobbe direkte på kildedataene.

I et slikt scenario så kan det være krav til WS-en i kilden om å tilby skrivemuligheter. Man kan se for seg at personpresentasjonen på UiOs nettsider vil være redigerbare for personer som er innlogget og disse dataene både hentes fra UiOs HR-system, samt blir skrevet tilbake hvis personen redigerer dem i presentasjonssidene. Dette gir strengere krav til oppetid og skalerbarhet i kilden og dens WS, men gevinsten er at selve tjenesten blir mindre og mindre kostbar – man oppdaterer kildedata direkte uten mellomlagring og ekstra kompleksitet dette medfører.
Hvordan skal et API i en WS se ut?
RESTful
REST er en metodikk for å sikre løse koblinger mellom to tjenester i en integrasjon. Begrepet misbrukes ofte om integrasjoner som benytter HTTP som den underliggende protokollen for integrasjonen, men REST er ikke begrenset til HTTP og må ikke bygges over HTTP. For å sikre at man ikke viderefører gamle, tett koblede integrasjoner i den nye integrasjonsarkitekturen, bør tjenesteeiere og -utviklere etterstrebe å lage grensesnitt som er så RESTful som mulig.
Så hva er RESTful? Det kan deles inn i fire nivåer, der det er opp til tjenesteeier og -utvikler å bestemme hvor RESTful API-et skal være. Anbefalt minimumsnivå er nivå 2.
Nivå 0: RPC over HTTP
På dette nivået ligger REST API-er som ikke egentlig er REST. Man har implementert typiske RPC-kall over HTTP og kaller dette REST. Det resulterende API-et blir spesialisert og lite gjenbrukbart. Typisk forsøker man å tilby funksjonalitet i API-et tatt helt bokstavlig fra en bestilling. Ønsker konsument en å hente fornavn på en person så lager man en funksjon for dette. Konsument to ønsker hele navnet så da lager man en ny funksjon. Konsument tre ønsker en liste med alle navnetyper, samt muligheten til å oppdatere navn så da lages det flere funksjoner for alt dette. Man ender opp med tette koblinger og lite til ingen gjenbruk.
Nivå 1: Ressurser
På nivå 1 begynner man å omfavne RESTful. Isteden for spesialiserte kall for enhver handling som omhandler en ressurs eller entitet så samler man disse i en felles ressurs. I eksemplet med navn på en person fra nivå 0 så samler man navn under persons/mathiasm/names. Under dette området samler man de funksjoner som omhandler navn. Dette er en bedre løsning enn i nivå 0, men fortsatt utsatt for spesialiserte funksjoner og manglende gjenbruk. Det oppfordrer dog til en ressursdrevet (datadrevet) modell der ressurser i form av data bestemmer mer av strukturen på API-et heller enn en mer tilfeldig modell basert på hvem som spurte om hva når.
Nivå 2: HTTP verb
På dette nivået har API-et modnet betraktelig. Om man implementerer et nivå 2 API så er ikke API-et fullt ut RESTful, men det er likevel av en slik kvalitet at det oppfyller kravene fra integrasjonsarkitekturen. Det vil være modulært, datadrevet og gjenbrukbart. Som de tidligere eksemplene med personnavn så vil HTTP-verbet bestemme operasjonen man gjør på navn. GET persons/mathiasm/names vil gi en liste URL-er med de navn som er registrert for personen 'mathiasm'. GET på en av disse vil gi denne typen navn. En endring eller sletting gjøres med HTTP-verbene DELETE, POST eller PUT. Behovet for spesialiserte funksjoner blir minimalt da dataene selv representeres som ressurser og man kan lese og skrive til disse ressursene.
Nivå 3: Hypermedia Controls/HATEOAS
For et ekte RESTful API så skal API-et i WS-en være den kontrollerende aktøren i integrasjonen. Dette vil si at i eksemplet med navn så vil utseendet på API-et endre seg i forhold til kontekst. For konsument 1, som kun skal hente fornavn på personer, så viser API-et kun dette. For konsument 3, som ønsker alle navnetyper, samt mulighet til å oppdatere navn, så vil kallet som returnerer listen også inkludere lenker til hvordan konsumenten kan oppdatere navn. For de navn som ikke finnes vil det bli sendt med lenker til hvor konsumenten kan opprette disse navnene. API-et gir fra seg informasjon om tilstanden på data og tilgangene konsumenten har til data. Dette gir navn til det velklingende akronymet HATEOAS (Hypertext As The Engine Of Application State).
Å implementere et ekte RESTful API er ressurskrevende. Det er uklart om steget fra nivå 2 til 3 er verdt den ekstra innsatsen.
Entitetsbasert API
Entitet- eller ressursbasert, som nevnt under nivå 1 under RESTful, handler om å bevege seg bort fra operasjonen man skal gjøre og heller se på data man skal gjøre noe med. Mange uttrekk og funksjoner i dag er resultatet av at man skal gjøre noe bestemt. Konsumenter trenger sammensatte uttrekk fra konsumenter og skal ikke ha for mye eller for lite data. Dataene skal formateres på bestemte måter og svært sjeldent kan to ulike konsumenter benytte de samme uttrekkene.
Å si at API-er skal være entitetsbaserte (evt. ressursbaserte) vil si at man heller eksponerer typiske entiteter fra kilden heller enn ferdige uttrekk. Om en konsument trenger informasjon om ansatte og deres organisasjonstilhørighet så kan dette realiseres med entitetene employees og organisational units. Relasjonen mellom den ansatte og organisasjon realiseres som attributter i en eller begge entiteter. Det er opp til eiere, forvaltere og utviklere for en kilde om hva som er en entitet eller ressurs. Eksempelvis kan man si at en brukerkonto er en entitet, mens et brukernavn kun er et attributt ved denne brukerkontoen. En gruppe er en entitet, mens gruppenavnet og medlemskap er attributter til gruppen.
Slike kolleksjoner av entiteter eller ressurser vil ikke gi den skreddersømmen som vi til vanlig har tilbudt. Det er nå opp til konsumenten å selv filtrere og slå sammen data, men kilden tilbyr nå verktøyene for at konsumenter kan få data.
For funksjoner som aldri kan være datadrevne – som start/stopp-funksjonalitet – er det opp til tjenesteeier for hvordan man realiserer dette.
Funksjonelt API
Et funksjonelt API, til forskjell fra funksjonell programmering, omhandler at designet av API-et skal være forståelig og brukbart for utenforstående. Utviklere av konsumenter sitter ikke med den domenekunnskapen som de som jobber med en kilde gjør. Dette betyr at API-er inn mot kilder bør forenkles slik at de gir mening for utenforstående, men ikke mer enn at informasjon som er nødvendig for konsumenter går tapt.
Et eksempel kan være den aktive studentmassen på UiO. Ulike konsumenter kan være interessert i ulike mengder studenter slik at API-et må gi et rikt utplukk studenter, men konsumentene vet ikke reglene som omhandler betalt semesteravgift, oppmeldt studieprogram eller enkeltemne, samt andre regler som bestemmer om studenter regnes som "aktive" studenter. API-et kunne realiseres som enten å ha et attributt som sier "aktiv" på ressursen student, eller eksponere alle tilhørende databasestrukturer som avgjør om studenten er aktiv i andre enden av skalaen. Sannsynligvis ligger den beste løsningen et sted i midten, der man bør eksponere mye av de tilhørende data, men på en slik måte at konsumenten kan forstå informasjonen heller enn å lære seg de interne strukturene i kilden.