En analyse av atmosfæren kan hjelpe oss å vite om det er mulig å puste der, finne hva slags stoffer vi kan forvente å se og senere bruke det til å modellere atmosfæren slik at vi kan ha en sikker landing på planeten.
Vi lar så først romskipet gjøre noen målinger før vi kan begynne å analysere de. Som vi vet, kan vi se på spektrallinjene fra atmosfæren og så springer naturlig ut alle gassene som er tilstede.
Ifølge maskinen her om bord vil denne analysen ta... ca. mer enn et år. Så vi har nok masse tid til å holde oss i en forhåpentligvis stabil bane- Nei, vent, der var den ferdig gitt. Det er vel det du får når du bruker Windows på rakett-PCen.
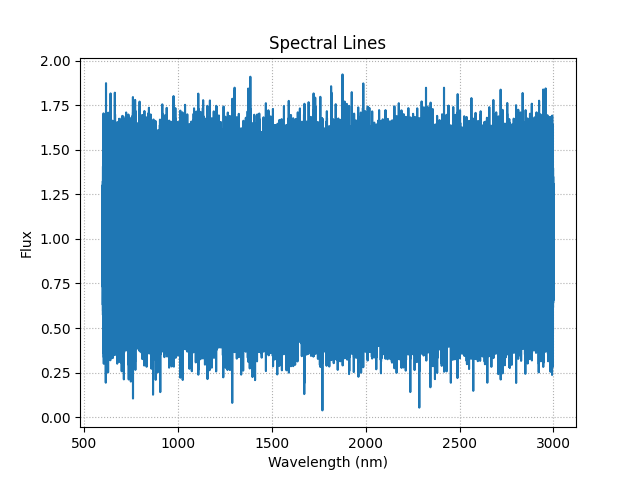
Dette var vel ikke så rett fram som det kunne ha vært, noen må ha glemt å legge på et støyfilter på måleapparatet. Vi må så fjerne denne støyen manuelt, og det kan vi gjøre ved å bruke et av de kraftigste verktøyene i spektroskopi, nemlig normalfordeling! Vi kan bruke dette ettersom vi har en jevn fordeling av støy og spektrallinjene er uavhengig av hverandre. Noe som vi kan godt anta i en ideell gass.
Hva vil vi så forvente å se? Det er klart at når vi ser på en gass med et svart legeme bak seg, vil vi få et absorpsjonsspekter ettersom at gassen vil absorbere noe av strålingen fra legemet før det når raketten. Derfor kan vi forvente å se et fall i fluksen hvis vi sier at kontinuumfluksen, eller fluksen vi ville normalt sett hvis det ikke var noe der i det hele tatt, lik 1. Ettersom måleinstrumentet vårt allerede har normalisert dataen rundt dette tallet. Makan til prioriteringsevne på de som bygde dette instrumentet.
\(Flux(\lambda) = Flux_{Continuum} + (Flux_{Minimum}-Flux_{Continuum})e^{-\frac{(\lambda-\lambda_0)^2}{2\sigma^2}}\)
Hvor vi må finne et uttrykk for avviket (σ). Hvis du husker hvordan vi fant avviket i normalfordelingen, så vet du at hvis vi antar at vi har en ideell gass så vil standardavviket være:
\(\sigma = \sqrt{\frac{kT}{m}}\)
Da vi ser på fluks istedet for antall partikler i en viss hastighet, kan vi modifisere dette til:
\(\sigma = \frac{\lambda_0}{c}\sqrt{\frac{kT}{m}}\)
Hva er så minimumsfluksen, temperaturen og bølgelengden til spektrallinjen? Godt spørsmål, for det vet ikke vi heller! Her gjelder det derfor å bruke enda en feilanalysemetode, nemlig kjikvadratmetoden. Hvorfor i alle dager bruker vi denne? I motsetning til midlere kvadratisk feil tar denne i betraktning at vi har støy.
\(\chi^2 = \sum\limits_{i=1}^N \left(\frac{data-Flux(\lambda)}{\sigma}\right)^2\)
Dermed er det bare å plukke å mikse alle verdier av minimumsfluks, temperatur og bølgelengder til vi får den minste kjikvadrat-feilen! Du trodde vel kanskje jeg skulle gjøre det? Nei, dette er mat for selveste Python! Allikevel har nok Python ikke lyst til å gå igjennom hele datasettet for hver eneste gang han prøver å finne en passende modell, vi gjør dermed jobben lettere ved å finne dopplerskiftet. Dette er hvor mye skift på absorpsjonslinjene vi vil forvente å se når vi suser rundt planeten. Dopplerskiftet er så kontraksjonen eller forlengingen av bølger når vi beveger oss mot eller fra gassen. Vi gjør en antakelse at vi ikke suser rundt i høyere fart en 10km/s, ettersom at dette er den galaktiske føderasjonens fartsgrense for lav omløpsbane og vi glemte lommeboka hjemme.
\(\Delta\lambda = \frac{v}{c}\lambda_0\)
Vi må dermed vite hva som er den absorpsjonslinjen vi ser etter, hvor den vanligvis ligger hvis det ikke er et skift. Heldigvis har vi en tabell for dette, og kan gi dette til Python.
| Stoff | Bølgelengde (nm) | ||
|---|---|---|---|
| Oksygengass (O2) | 632 | 690 | 760 |
|
Vann (H2O) |
720 | 820 | 940 |
| Karbondioksid (CO2) | 1400 | 1600 | |
| Metan (CH4) | 1660 | 2200 | |
| Karbonmonoksid (CO) | 2340 | ||
| Dinitrogenoksid (N2O) | 2870 | ||
Så hva sier vår matematiske slange? Han gir oss mange modeller, men her må vi vurdere selv om de er riktige absorpsjonslinjer eller ren feil:
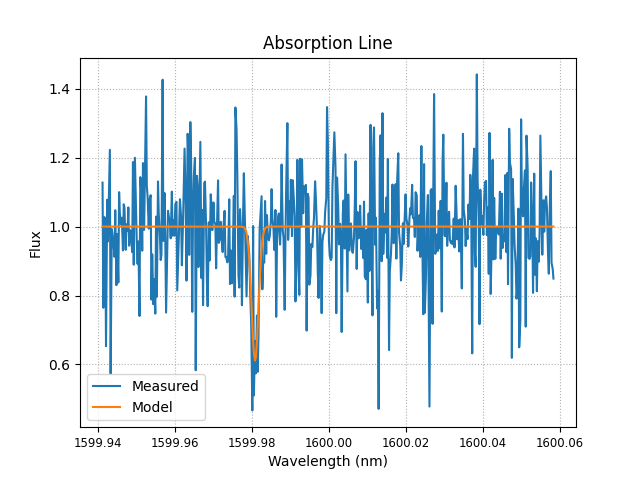
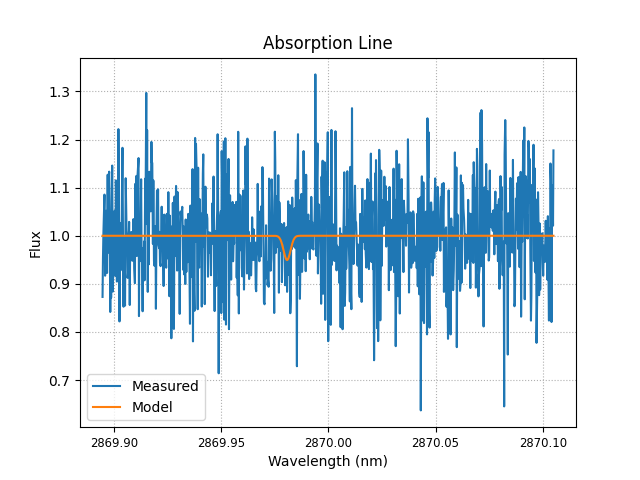
Vi ser så at noen kan stemme, men noen mest sannsynlig bare er støy. Vi vet også at de som har en minimumsfluks på under 0.7, er mest sannsynlig en god kandidat for en gyldig absorpsjonslinje. Likevel ser vi ikke bort fra de i 0.8, men vi kan se bort fra de som er langt oppe i 0.9.
Hvilke absorpsjonslinjer gjelder da? Det kan være vanskelig å få dette helt rett, men ved antakelser av hvilke absorpsjonslinjer kan være rett får vi at det finnes karbondioksid, vann og oksygen. Hvor to av de var karbondioksid og en for vann og oksygen. Vi gjør så en grov antakelse fra dette settet med data er likt fordelt slik at det er \(\frac{1}{3}\%\) av hvert stoff. Vi kan så finne en midlere molekylvekt i denne atmosfæren:
\(\mu = \sum\limits_{i=1}^N f_i\frac{m_i}{m_H}\)
Hvor fi er prosentdelen vi har av stoffet i atmosfæren og mi er massen til stoffet.
\(\mu = \frac{\frac{1}{3}\cdot44+\frac{1}{3}\cdot16+\frac{1}{3}\cdot18}{1}=26\)
Og da har vi gjort hele jobben til den som hadde glemt å installere støyfilteret på måleapparatet, men kanskje det lønte seg allikevel ettersom vi fikk gå igjennom all den fine matematikken bak den. Derimot må vi likevel ta i betrakning at det kan være feil når vi bare har ett datasett. Det er ikke lett å verifisere om dataen er riktig, og en mulig feil Python ga oss var at temperaturene som passet best til dataen ofte var ekstremalverdier. Det som vi satt som minimum- og maksimumstemperatur for gassene. Altså så kaldt som 150K eller så varmt som 450K, bare noen få lå inn i mellom. Dette kan være en mulig feilkilde for hvilke kjikvadrattall vi får, og dermed gi oss feil absorpsjonslinjer.